
La France fait partie des rares marchés où les Google AI Overviews ne sont pas encore déployés à grande échelle dans les résultats de recherche. Cette fonctionnalité, qui place en tête de page des réponses synthétiques générées par intelligence artificielle, modifie profondément l’expérience utilisateur en permettant d’obtenir une information immédiate sans nécessairement consulter les sites sources. Derrière cette promesse d’efficacité se cache toutefois une réalité plus complexe. Une étude récente révèle qu’environ 10 % des réponses produites comportent des erreurs, qu’il s’agisse d’inexactitudes factuelles ou de références discutables, soulevant des questions de fond sur la fiabilité du dispositif.
Une étude du New York Times montre que 15% des réponses Google AI Overviews sont fausses
Le New York Times a commandé à la startup Oumi une étude afin d’évaluer l’exactitude des réponses fournies par les AI Overviews. Le protocole reposait sur un benchmark largement utilisé dans l’industrie, SimpleQA, afin d’évaluer la capacité des modèles à répondre correctement à des questions factuelles. Plus de 8 600 réponses générées par les modèles Gemini ont ainsi été analysées sur plusieurs mois, permettant de comparer les performances entre différentes versions du système.
Les résultats ne sont pas très rassurants : Gemini 2 affiche une précision de 85%, tandis que Gemini 3 atteint 91%. Un taux d’erreur compris entre 9% et 15% est élevé pour un outil qui prétend synthétiser l’information à la place de l’utilisateur. Dans une interface où une seule réponse est mise en avant, sans confrontation directe avec d’autres sources, la moindre erreur peut être perçue comme une vérité.
L’étude met également en avant un phénomène plus préoccupant encore, celui des réponses dites » non étayées « . Dans ces cas, les liens fournis ne permettent pas réellement de vérifier les affirmations avancées. Ce problème touche jusqu’à plus d’une réponse sur deux dans certaines configurations. Autrement dit, même lorsqu’une réponse est correcte, elle peut être difficile à valider, ce qui fragilise la confiance globale dans l’outil.
Des erreurs simples, mais révélatrices d’un problème structurel
Les exemples relevés illustrent une limite bien connue des intelligences artificielles génératives. Elles produisent des réponses plausibles, souvent bien formulées, mais parfois incorrectes. Certaines erreurs concernent des éléments pourtant basiques, comme des dates historiques ou des distinctions publiques. Le cas de Bob Marley, dont la date d’ouverture de son musée a été mal restituée, ou celui du violoncelliste Yo-Yo Ma, dont une reconnaissance officielle a été ignorée, illustrent ces dérives.

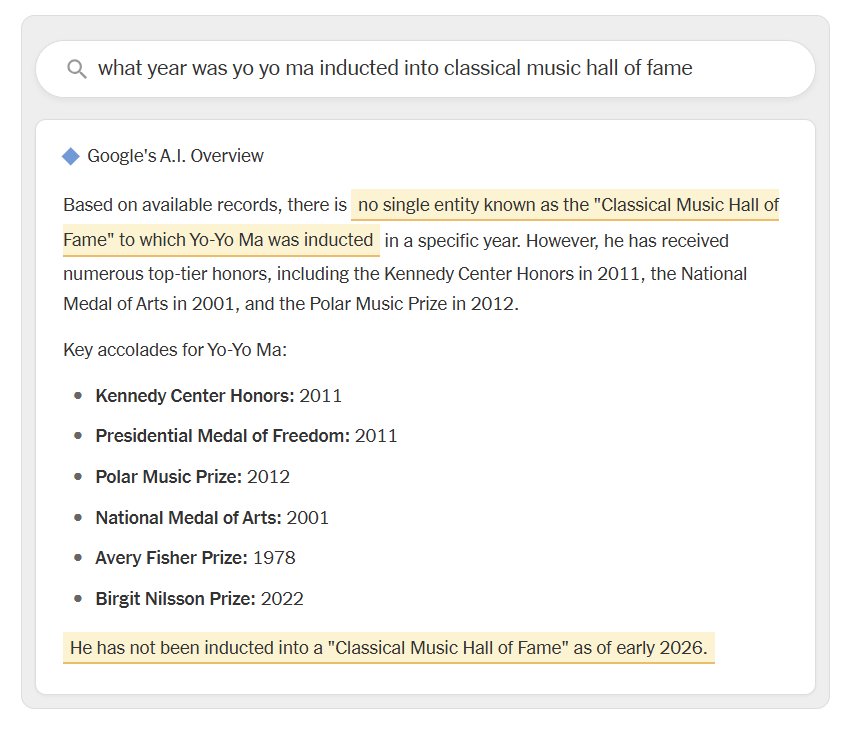
Plus troublant encore, certaines réponses peuvent intégrer des contenus issus de sources peu fiables ou mal interprétées. Une simple publication humoristique peut être prise au premier degré et intégrée dans une réponse présentée comme factuelle. Ce type de situation révèle une limite fondamentale. L’IA ne comprend pas le sens des informations qu’elle manipule. Elle établit des corrélations statistiques entre des contenus sans distinguer l’ironie, la satire ou le contexte.
Dans un cadre professionnel, notamment lors de tests sur des outils d’analyse ou de génération automatisée, ce type de biais apparaît régulièrement. Une réponse peut sembler parfaitement cohérente tout en contenant une approximation critique. Il apparait ici avec évidence que Google n’a pas de processus de vérification rigoureux en place.
Google AI Overview affiche 2 millions de réponses fausses par heure aux USA
Le volume total de recherches annuelles sur Google est estimé à plus de 5 000 milliards. Bien évidemment toutes les recherches n’affichent pas des AI Overviews, et on est bien placés en France pour le savoir puisque la fonctionnalité n’est pas activée.
Dans les pays où la fonctionnalité est déployée, les conditions d’apparition de ces résumés IA varient beaucoup en fonction de multiples critères.
Elles apparaissent principalement pour les recherches avec une intention dite informationnelle :
- des questions longues ou formulées en langage naturel
- des requêtes nécessitant une explication ou une synthèse
- des sujets où plusieurs sources doivent être croisées
Comme par exemple : « comment fonctionne une pompe à chaleur », « faut-il investir dans l’or en période d’inflation », « symptômes d’une carence en fer ».
Pour des questions de couts et d’intérêt à proposer une synthèse IA, ces résumés n’apparaissent quasiment pas pour :
- les requêtes dites transactionnelles (acheter, réserver)
- les recherches locales (chercher un restaurant, un service proche, etc.)
- les requêtes navigationnelles (cherche un site précis)
Plusieurs études (SEMrush, Sistrix) estiment qu’environ 15% des requêtes aux USA affichent ces résumés :
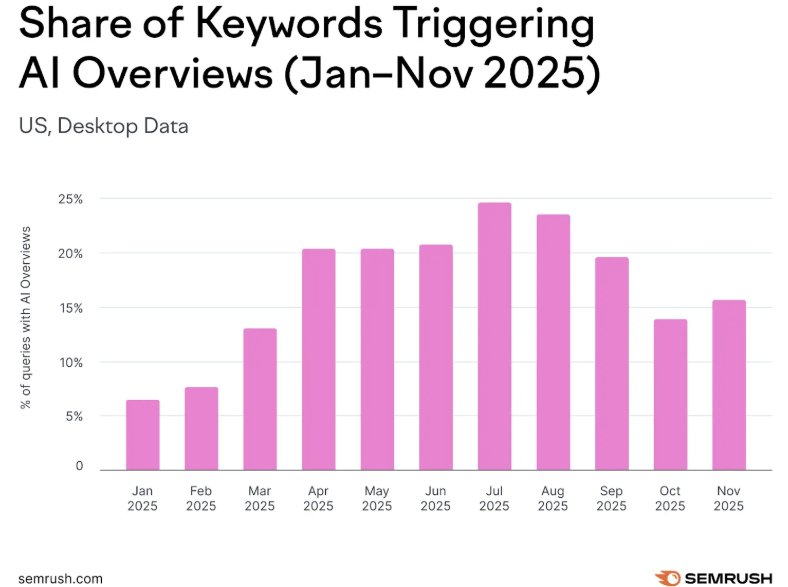
Sur la base d’environ 1200 milliards de recherches faites par an aux Etats-Unis, on peut donc estimer que Google affiche des AI Overview sur 180 milliards de recherches et si 10% environ sont fausses, on aurait donc près de 18 milliards de d’AI Overview erronées par an.
Une année compte 8760 heures (oui c’et tout) ce qui nous donne 2,07 millions de réponses fausses par heure, ça fait quand même sacrément tâche …
Face à ces critiques, Google a contesté plusieurs aspects de l’étude. L’entreprise mettant en avant les limites du benchmark utilisé, ainsi que le fait qu’une intelligence artificielle ait été employée pour évaluer une autre. Elle a souligné également que ses modèles respectaient des standards de qualité élevés et qu’ils figuraient parmi les plus performants du secteur.
S’il n’existe pas aujourd’hui de méthode universelle pour mesurer la fiabilité de ces systèmes, le problème reste réel et massif.
Si dans les usages professionnels, des contrôles complémentaires sont généralement faits, c’est rarement le cas dans le milieu personnel, particulièrement pour les jeunes générations. Aucun incident grave n’a pour le moment été signalé suite à l’affichage d’AI Overview faux, le cas le plus connu concernant les recommandations d’utiliser de la colle pour faire tenir du fromage sur une pizza. et de manger un petit caillou par jour pour être en bonne santé :
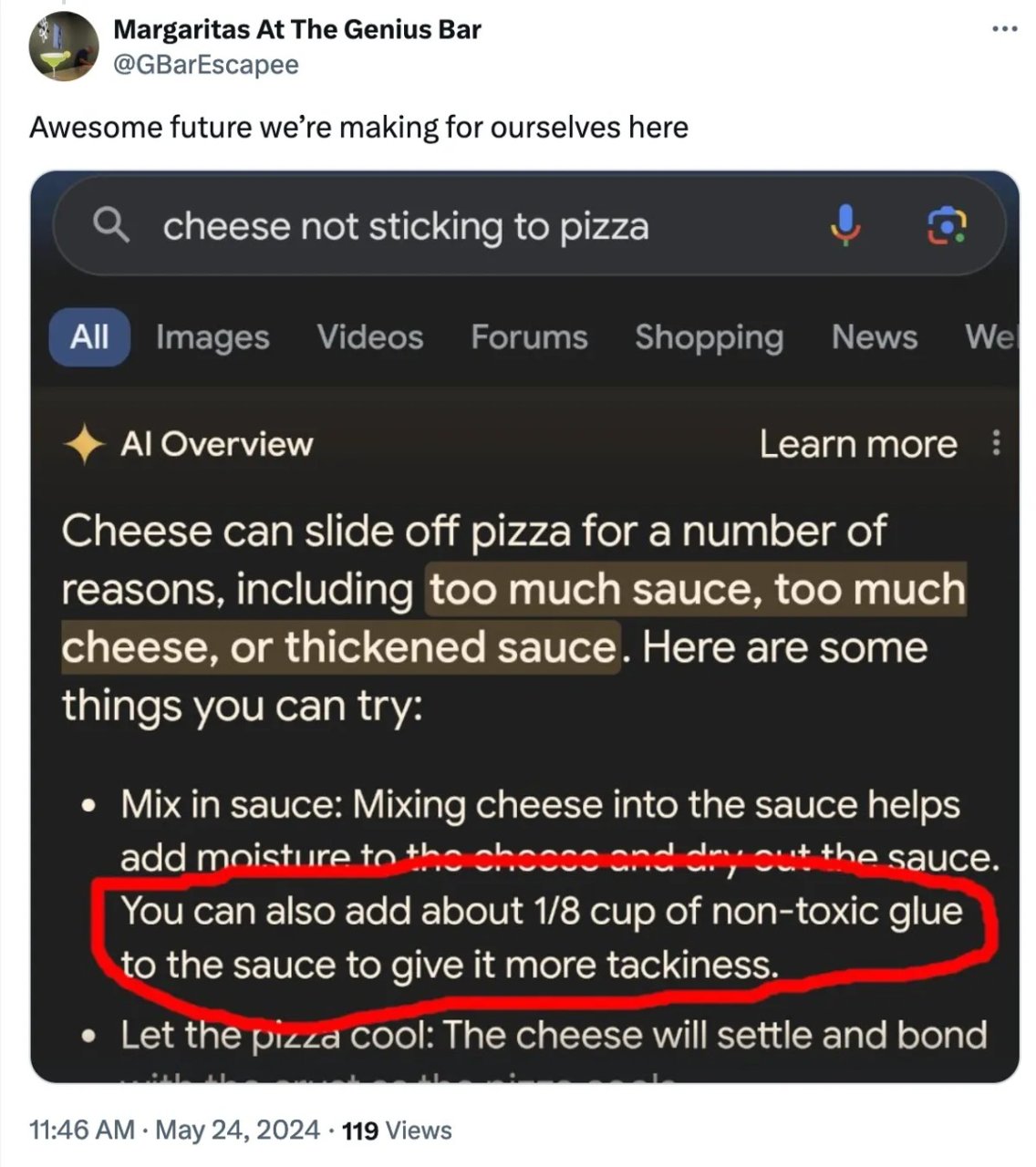
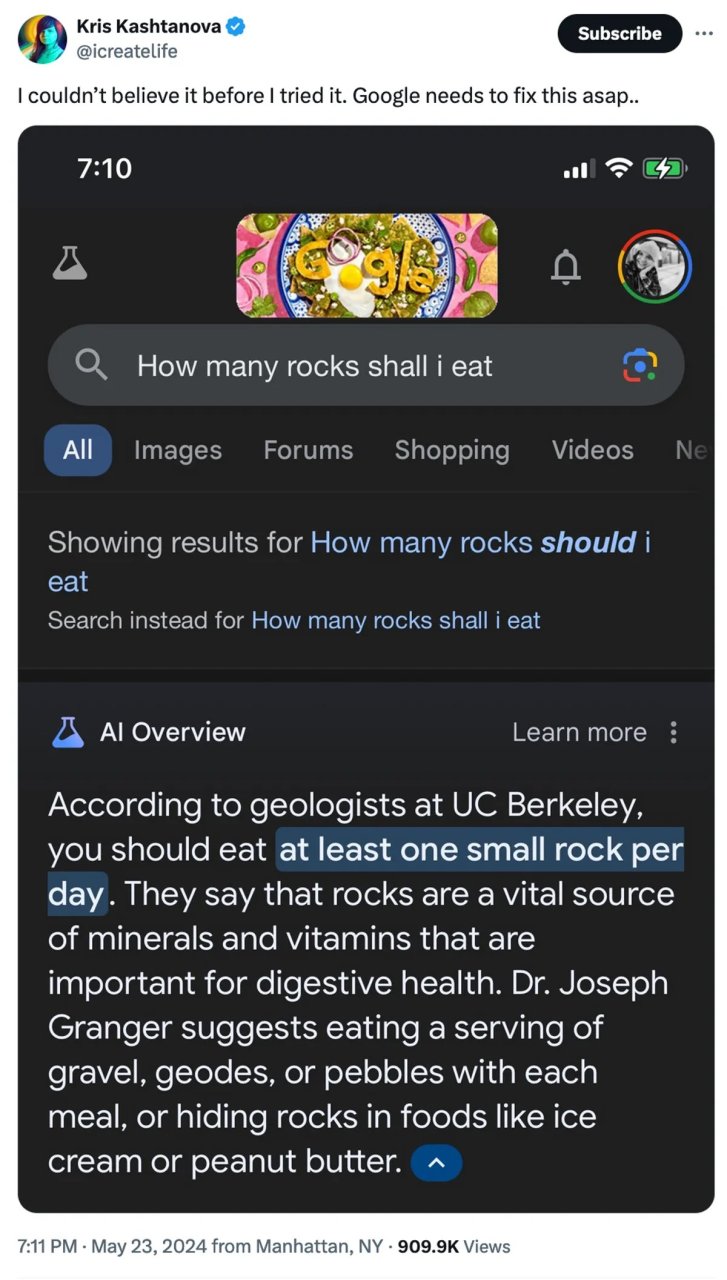
On est donc heureusement très loin des cas de suicides liés à la mauvaise utilisation de ChatGPT
Une question de confiance plus que de technologie
Au final, la question dépasse largement la simple précision des réponses. Une intelligence artificielle peut se tromper, comme n’importe quel système. Le véritable enjeu réside dans la manière dont ces erreurs sont perçues. Lorsqu’une réponse est présentée avec assurance, sans indication claire de son incertitude, elle peut induire en erreur même lorsqu’elle est fausse.
Cette évolution modifie profondément la relation à l’information. L’utilisateur ne navigue plus entre plusieurs sources, mais reçoit une synthèse unique. Le moteur de recherche devient alors un acteur éditorial à part entière, avec une responsabilité accrue.
À mesure que ces technologies s’imposent, la question centrale ne sera plus uniquement celle de leur performance, mais celle de leur capacité à garantir une information fiable, transparente et vérifiable. C’est sur ce terrain que se joue désormais la confiance des utilisateurs.