# Les agents IA coûteront plus cher que les humains (Etude Goldman Sachs)

**Date:** 25 juillet 2026
**Source:** [PIX GEEKS](https://pix-geeks.com)
**Catégories:** [High-Tech](https://pix-geeks.com/tech/) > [Intelligence Artificielle](https://pix-geeks.com/tech/intelligence-artificielle/)
**Étiquettes:** [Emploi](https://pix-geeks.com/dossier/emploi/), [Étude](https://pix-geeks.com/dossier/etude/)
**Les modèles d’intelligence artificielle gagnent en puissance chaque jour, les coûts de calcul baissent et les usages se démocratisent. Cette dynamique qui séduit autant les financiers qu’elle inquiète les salariés est peut-être sur le point de s’inverser. Selon une étude récente de Goldman Sachs les agents IA pourraient couter à moyen terme plus cher que de vrais employés physiques.**
- Les coûts des agents IA pourraient devenir plus élevés que ceux des humains d'ici 2030.
- La consommation de tokens par les IA augmente fortement, malgré la baisse des prix par token.
- Des techniques comme RAG, mémoire persistante ou compression réduisent certains coûts mais compliquent l'efficacité.
Si vous avez déjà utilisé des agents IA ou même de simples MCP vous savez que la consommation en tokens de ces outils flambe rapidement. Or [l’étude de Goldman Sachs](https://www.goldmansachs.com/insights/articles/ai-agents-forecast-to-boost-tech-cash-flow-as-usage-soars) met en évidence que la baisse des coûts unitaires des calculs IA ne suffira pas à compenser la croissance de ces usages à horizon 2030.
## La consommation en tokens des IA sera multipliée par 24 d’ici 2030
Lorsqu’une ressource devient moins coûteuse, son utilisation augmente souvent beaucoup plus vite que les gains d’efficacité qu’elle fournit :
- Les moteurs deviennent plus économes, mais davantage de véhicules circulent
- Les connexions Internet deviennent plus rapides, mais les vidéos deviennent plus lourdes
- etc
Le même phénomène a donc toutes les probabilités de se produire avec l’intelligence artificielle : même si le cout unitaire des tokens baisse régulièrement, le nombre total de tokens consommés va croître de façon exponentielle avec le développement de l’agentique.
D’après Goldman Sachs, la consommation globale de tokens sera multipliée par 24 d’ici 2030 :
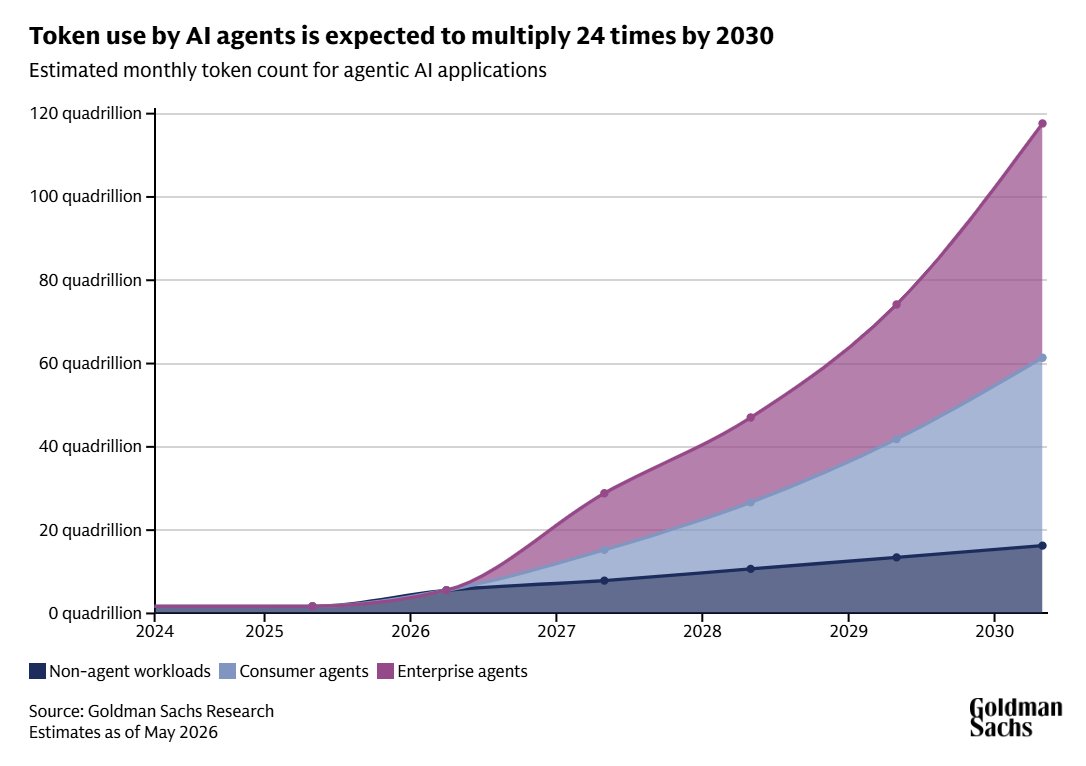
### Evolution de la consommation de tokens d’ici 2030
| | Projections |
| --- | --- |
| Consommation de tokens | x 24 à 2030 |
| Volume mensuel estimé | 120 quadrillions de tokens |
| Croissance annuelle des requêtes LLM | +40% |
| Utilisation des agents chez les travailleurs du savoir en 2030 | +12 % |
| Utilisation en 2040 | +37% |
| Baisse annuelle du coût d’inférence | +60 à +70 % |
| Pénurie attendue de puces IA | 12 à 18 mois |
## Pourquoi les agents IA consomment-t-il autant de tokens ?
Un **assistant conversationnel** comme ChatGPT suit généralement un schéma relativement simple : une question entre, elle déclenche éventuellement une phase de **deep thinking** ou des **recherches web**, une réponse sort, puis le cycle s’arrête et **la consommation de token reste modérée**.
Un **agent autonome** fonctionne différemment : ce qui ressemble à une demande unique déclenche **plusieurs dizaines d’opérations invisibles, chacune consommant des ressources**.
Un agent peut par exemple :
- consulter des documents
- appeler plusieurs API et MCP
- analyser des données
- générer du code
- vérifier son propre résultat
- puis recommencer certaines opérations lorsqu’il détecte une anomalie
Depuis quelques mois sont également apparus des **frameworks agentiques** comme [OpenClaw](https://pix-geeks.com/histoire-inspirante-peter-steinberger-openclaw-rejoindre-openai/), [Hermes](https://hermes-ai.net/) ou [PaperClip](https://paperclip.ing/)\.Ils permettent de construire des organisations composées d’agents spécialisés auxquels sont attribués des rôles.
Prenons l’exemple d’un magazine en ligne, il peut utiliser un framework constitué de ces agents pour gérer le cycle de publication des articles :
- **Agent rédacteur en chef** : reçoit un sujet, définit l’angle et distribue les tâches
- **Agent de recherche** : récupère les sources, chiffres, tendances et actualités
- **Agent de fact-checking** : vérifie les informations et détecte les incohérences
- **Agent de rédaction** : rédige l’article selon le style éditorial
- **Agent SEO** : optimise titres, mots-clés, maillage et métadonnées
- **Agent d’illustration** : génère ou sélectionne images et idées visuelles
- **Agent de publication** : envoie vers WordPress, ajoute catégories et planifie la mise en ligne
Le nombre total d’opérations exécutées au sein de cette organisation pour accomplir la macro tache **publier un nouvel article** est donc d’un ordre de grandeur très élevé.

Il existe par ailleurs un biais important : **davantage de ressources ne garantit pas forcément un meilleur résultat** si les règles d’orchestration ne sont pas bien définies ou si les bons garde fous ne sont pas mis en place.
Un agent mal cadré risque de :
- relire plusieurs fois les mêmes informations
- effectuer des étapes redondantes
- effectuer des boucles inutiles
- partir sur des méthodes de résolution inadaptées et fournir des solutions trop complexes, voire instables
A mesure que les organisations agentiques se complexifient le nombre de ces dérapages augmente. Il devient rapidement plus compliqué d’améliorer ces process sans générer de régression que de réinitialiser simplement les taches en erreur.
Prenons l’exemple d’articles générés par IA en masse, certains seront de mauvaise qualité. On pourrait écrire de nouvelles règles pour traiter les cas marginaux, mais ce sera une tache longue et complexe, et on se retrouvera vite avec **une énorme liste de cas particuliers rares totalement ingérable**\.Il sera nettement plus efficace d’ajouter une étape finale de contrôle qualité et de régénérer directement chaque article en erreur.
Pour augmenter la qualité globale des réponses, les systèmes agentiques ajoutent souvent des étapes supplémentaires : raisonnement, appels d’outils, recherches externes, mémoire ou vérifications intermédiaires. Cette sophistication augmente la consommation de ressources et peut même rendre certains usages difficiles à justifier économiquement.
Dans certains cas très spécifiques, notamment pour des demandes complexes nécessitant beaucoup d’étapes ou une forte supervision, **un opérateur humain externalisé peut revenir moins cher qu’un framework agentique avancé**.
## Des architectures existent déjà pour réduire les couts de l’IA agentique
ChatGPT a été lancé fin 2022 il y a moins de 4 ans, et depuis l’écosystème IA a subi de nombreuses révolutions : nouveaux modèles, nouveaux agents et nouveaux outils se succèdent à une vitesse vertigineuse. Alors que les coûts chutent régulièrement et que de nouvelles architectures émergent chaque mois, faire des projections à 5 ans est donc un exercice périlleux.
Ajoutons à cela qu’il existe déjà des solutions permettant de réduire significativement le cout des processus IA agentiques.
### Les Retrieval Augmented Generation (RAG)
Les systèmes de type **RAG** (Retrieval Augmented Generation) modifient profondément l’utilisation du contexte des opérations IA. Ils permettent de récupérer uniquement les passages réellement utiles à la réalisation d’une tâche, et de transmettre à un LLM cet extrait plutôt que d’envoyer des documents complets à chaque demande.
### Les mémoires persistantes
Des mécanismes de **mémoire persistante** permettent aux agents IA de conserver certaines informations importantes en mémoire sans devoir tout relire à chaque nouvelle tâche. Une solution comme [Claude-mem](https://github.com/thedotmack/claude-mem) permet, au prix de temps de réponse dégradés, de faire des économies très significatives (jusqu’à **95% d’économie de tokens**) .
Des solutions d’orchestration agentique, situées à mi-chemin entre le RAG et la mémoire persistante, permettent également de réaliser des économies significatives :
### Le routage intelligent par complexité
Utiliser un modèle IA **frontier** (ce qui se fait de mieux) pour toutes les tâches revient fréquemment à gaspiller des ressources pour résoudre des problème élémentaires.
Pour effectuer un calcul arithmétique simple, **GPT-5.5 coûtera 70 fois plus cher que GPT-4.1 nano** et fournira exactement la même réponse.
À l’inverse, pour traiter un fichier client de **50 Mo**, un petit modèle aura tendance à traiter directement une grande quantité de données dans son contexte et consommera des millions de tokens. Un modèle de raisonnement plus avancé comme GPT-5.5 choisira probablement de créer un outil Python pour préparer les données avant traitement ou même générer le traitement en programmatique pure (sans calculs IA). Malgré un coût plus élevé par token, cette approche **réduira la facture finale par 20** dans certains cas.
Ainsi, le modèle le moins cher n’est pas toujours celui qui pèse le moins sur la facture : **la stratégie de traitement compte autant que le prix des tokens.**
Des systèmes de routage par complexité comme [LiteLLM](https://www.litellm.ai) ou [LLMRouter](https://github.com/ulab-uiuc/LLMRouter) se chargent d’évaluer quel modèle sera le plus adapté pour traiter efficacement au meilleur prix une demande :
- ils évaluent d’abord la complexité réelle de la demande
- puis choisissent automatiquement le modèle et la stratégie les plus adaptés afin de réduire les coûts globaux, de limiter la consommation de tokens et d’accélérer l’exécution
### La compression sémantique
Dans les architectures multi-agents, une autre technique gagne aussi du terrain : la **compression sémantique** des échanges entre agents. Plutôt que de transmettre des instructions longues en langage naturel complet, certains systèmes restructurent ou résument automatiquement les informations échangées.

Le repo [Caveman Compression](https://github.com/wilpel/caveman-compression) qui supprime tous les mots de liaison inutiles à la compréhension des messages a beaucoup fait parler de lui ces dernières semaine : il permet de réduire la consommation de tokens jusqu’à **58%** dans les échanges d’informations entre agents IA.
## Le marché de l’emploi pourra-t-il échapper à la révolution IA ?
Les approches permettant de réduire la consommation en tokens des infrastructures agentiques existent déjà et elles ne se limitent pas aux méthodes d’orchestration. Il faut aussi compter sur des avancées directement intégrées aux modèles eux-mêmes, comme les architectures **Mixture of Experts (MoE)**, les techniques de **quantification** ou encore la **distillation de modèles**, qui visent à réduire les besoins en calcul tout en conservant des performances élevées. L’explosion annoncée de la consommation de tokens ne se traduira donc pas mécaniquement par une hausse proportionnelle des coûts.
Même si le volume de tokens consommés devrait fortement progresser dans les prochaines années, il reste extrêmement difficile d’en mesurer précisément l’ampleur et d’anticiper les coûts réels qui en découleront pour les entreprises. Entre l’amélioration des modèles, l’optimisation des infrastructures et l’évolution des usages, plusieurs variables continuent d’évoluer simultanément.
Un point semble toutefois beaucoup moins incertain : l’adoption industrielle des agents IA paraît difficile à éviter. Leur capacité à exécuter un grand nombre de tâches à grande échelle, en continu, vingt-quatre heures sur vingt-quatre, avec une vitesse supérieure à celle des humains et [une marge d’erreur potentiellement comparable](https://pix-geeks.com/overviews-10-reponses-ia-google-fausses/), constitue un avantage économique considérable. Dans ce contexte, il devient difficile d’imaginer que certains métiers du secteur tertiaire parviennent à échapper à une transformation profonde au cours des 5 prochaines années.
[Post X](https://twitter.com/_vmlops/status/2058009381422412240)
---
**Article précédent:** [Gemini est utilisable sur Google Home en France : comment l'activer, quelles nouvelles fonctionnalités ?](https://pix-geeks.com/gemini-deploye-google-home-france-activer-fonctionnalites/) | **Article suivant:** [Google devient un moteur de recherche IA avec trafic SEO divisé par 3](https://pix-geeks.com/google-ia/)